Data Engineering is a Cost-Saving Catalyst in Agentic AI
Data engineering powers Agentic AI by delivering clean, structured, and purpose-ready data. Efficient pipelines and pre-aggregation reduce compute costs, speed up decision-making, and scale autonomy—turning backend optimization into a key driver of intelligent, cost-effective systems.
Agentic AI—systems capable of autonomous decision-making, perception, and action—represents a significant leap forward in artificial intelligence. These agents can plan, reason, and adapt with minimal human intervention, making them ideal for complex environments like robotics, real-time analytics, and autonomous operations. But behind their apparent independence lies a less glamorous, often overlooked discipline: data engineering.
As the engine room of any AI system, data engineering structures, cleans, and optimizes the flow of information. When done right, it dramatically reduces the cost of running and scaling Agentic AI. In this article, we explore how and why data engineering is pivotal to the economic viability of autonomous systems.
The Cost Problem in Agentic AI
Deploying agentic systems is expensive. Not just because of the models themselves, but due to:
- High-volume, high-variety data demands
- Heavy compute for real-time or continuous inference
- Frequent retraining and system updates
- Latency and reliability constraints in dynamic environments
These factors generate ongoing operational costs that scale with the system’s complexity and autonomy. And while model optimization helps, it doesn’t address the upstream problem: data inefficiencies.
How Data Engineering Reduces Cost
Efficient Data Pipelines Reduce Latency and Overhead
Agentic AI often relies on real-time or near-real-time data ingestion and inference. Manually orchestrated data flows are brittle and inefficient. Automated, optimized pipelines:
- Minimize compute cycles spent on redundant transformations
- Enable faster decision-making (critical in robotics and trading)
- Reduce developer time spent on debugging or maintaining data flows
This directly cuts down infrastructure and personnel costs.
2. Better Data Quality Means Less Model Tuning
A surprising amount of model performance comes not from architecture tweaks, but from better data. Clean, consistent, and well-labeled data means:
- Fewer training iterations needed
- Less time spent correcting model behavior post-deployment
- Lower frequency of costly retraining cycles
Data engineering enforces data quality through validation, schema enforcement, and anomaly detection—front-loading intelligence into the system.
3. Scalable Infrastructure Avoids Waste
Smart data partitioning, storage tiering (e.g., cold vs. hot data), and streamlining data lineage tracking prevent the ballooning of cloud storage and compute costs. It also allows multiple agent systems to access shared resources efficiently, supporting scalability without linear cost growth.
Observability for Optimization
Modern data engineering incorporates monitoring tools that provide visibility into data flows and bottlenecks. For Agentic AI, this means:
- Easier debugging of errant behavior (is it the model or the data?)
- More predictable system performance
- Lower mean time to resolution (MTTR) for failures
The result is reduced downtime and less need for costly manual intervention.
Real-World Impact
Organizations embedding data engineering into their AI lifecycle report substantial savings. For example:
- Autonomous logistics platforms using streaming ETL and schema registries have cut their cloud costs by over 40%.
- Agentic systems in financial services have reduced model drift-related retraining expenses by automating data quality enforcement upstream.
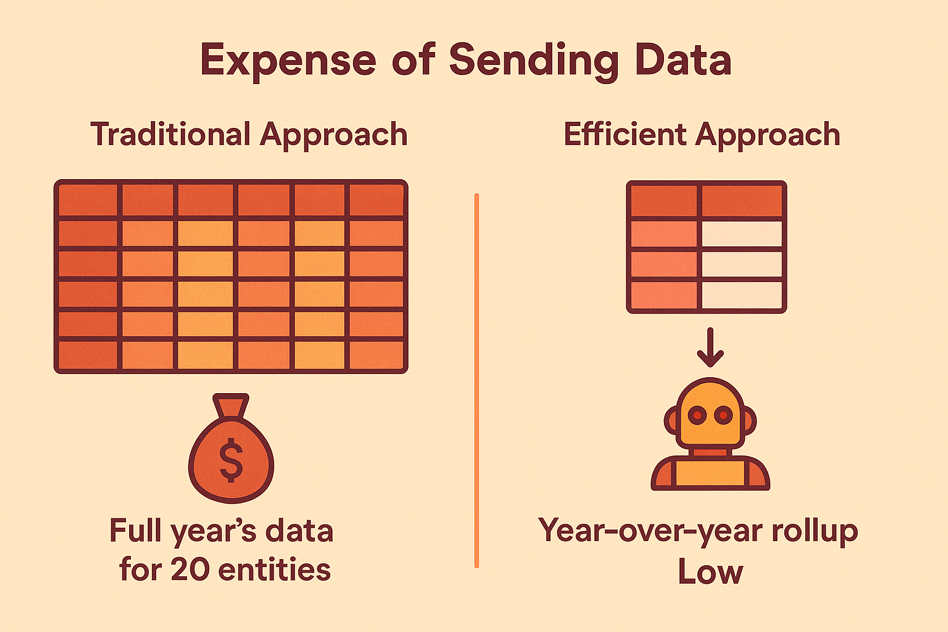
Imagine a business analyst needs to compare year-over-year performance metrics—like sales, customer growth, or retention rates—for 20 different entities (stores, users, or departments). A traditional approach might involve extracting and transmitting all relevant data points across multiple years, dimensions, and entities to a large language model (LLM) like OpenAI’s GPT or Google’s Gemini.
This results in a massive payload: every entity × every dimension × every year, creating a costly, slow, and redundant process. In contrast, a well-architected data model—using a star schema—can pre-aggregate this information into a year-over-year (YoY) roll-up table. Rather than asking the LLM to compute the comparisons from scratch, the AI agent receives a compact, curated dataset and is simply asked to help analyze or select insights from the precomputed values. This strategic data minimization drastically reduces both the data sent and the cost of computation, without sacrificing analytical power.
Conclusion: Intelligence Needs Infrastructure
As we move toward increasingly autonomous systems, it’s easy to get caught up in the sophistication of agent architectures, reinforcement learning, or multi-modal planning. But none of that is sustainable without a robust, cost-efficient data backbone.
Effective data engineering isn’t just about keeping the lights on—it’s a strategic enabler of affordable, scalable intelligence. In the race to deploy Agentic AI, those who master data infrastructure will have a significant economic and operational edge.